במאמר הפעם נצלול עמוק יותר לתת תחום יצירת התמונות מתוך התחום הרחב שנקרא בינה מלאכותית ג'נרטיבית בו עסקנו בפרק הקודם.
אין כאן כוונה ללמד או להבין את אלגוריתמיקה שעומדת בבסיס המודלים של הבינה המלאכותית הג'נרטיבית אלא ליצר מסגרת הבנה כללית של תהליכי יצירת תמונות על ידי בינה מלאכותית, ידע שיסייע לנו לנסח הנחיות טובות יותר בכדי לקבל את התמונה שאנו מנסים להשיג.
מלמדים מכונות ל"הבין" תמונות (זיהוי וסיווג אובייקטים בתמונה)
כשאר התחילו ללמד מכונות לנתח תמונות עוד לא חשבו על התחום של בינה מלאכותית ג'נרטיבית, אבל בכדי לאפשר את ה"קסם" הזה שיוצר תמונות באמצעות הנחיות (Prompts) מילוליות השלב המקדים הזה היה הכרחי.
אם אנחנו רוצים להגדיר למכונה מה ל"צייר" לנו, יש צורך ללמד אותה להבין מה אנחנו מבקשים, אבל בעיקר ללמד אותה ל"הבין" שהתמונה שהיא יצרה אכן משקפת את מה שביקשנו. לצורך כך נחזור אחורה בזמן למודלים הראשונים לסיווג תמונות שפותחו בסוף שנות ה-50 ותחילת שנות ה-60.
מודלים מוקדמים אלו היו פשוטים יחסית ובעיקר זיהו קצוות של עצמים בתמונות או אזורים כללים על פי צבע וטקסטורה, מה שהציג קווי מתאר כללים של האלמנט בתמונה. מודלים אלו שימשו בעיקר לתאור של המוטיב המרכזי בתמונה. בשפה המקצועית - Image Classification.

מודל Marr-Hildreth לסיווג תמונות שפותח על ידי דיוויד מאר (David Marr) ועמיתיו במכון הטכנולוגי של מסצ'וסטס (MIT) בסוף שנות ה-50.
ככל שהמחשבים הכפו חזקים יותר, תחום הראייה הממוחשבת ולמידת המכונה התקדם והתפתח מה שאפשר לשפר את המודלים של סיווג התמונות כך שהם יוכלו לזהות ולמקם אובייקטים שונים בתוך תמונה אחת (Image object detection).
התהליך של זיהוי אובייקטים בתמונה מתחיל באימון מודל למידת מכונה (Machine Learning) באמצעות מערך נתונים, שהוא למעשה אוסף של הרבה מאד תמונות המכילות את האובייקטים שאנו רוצים לזהות והמיקום הספציפי של אותם אובייקטים בתוך התמונה.

לדוגמה, אם המטרה שלנו היא לזהות את הגנבים והבלשים בתמונות, מערך הנתונים יהיה מורכב מהרבה מאד תמונות הכוללות דמויות בתנוחות גוף שונות ובמיקומים שונים, כאשר המיקום של הדמויות מסומנות (ב-קורדינטות) בתוך התמונה. המודל לומד לזהות את האובייקטים הרצויים בתמונות, במקרה שלנו בלשים וגנבים, על ידי למידה של המאפיינים והתכונות הייחודיות (צורה, גודל, צבע, מימדיים ועוד הרבה מאד פרמטרים שונים) שמאפיינות את אותם אובייקטים.
לאחר אימון המודל, ניתן להשתמש בו כדי לזהות אובייקטים בתמונות חדשות. כך, כאשר המודל מקבל תמונה חדשה הוא יוצר קבוצה של תיבות (וירטואליות שמסמנות את הקורדינטות בתמונה) סביב האזורים שלדעת המכונה כוללים את אותם אובייקטים רצויים. עבור כל תיבה בתמונה המודל מציין בצורה מספרית עד כמה הוא בטוח שאותו אזור מסומן מכיל את האובייקט הרצוי.

* המחשת התוצאה, בפועל האחוז מתקבל בקוד מספרי המצורף לנתוני התמונה.
עכשיו כשכבר יש לנו את היכולת לזהות אובייקטים שונים בתמונה, חוקרי הבינה המלאכותית בחנו כיצד ניתן ללמת את המוכנה להבין את ה"משמעות" של אותם אובייקטים שזיהינו.
לצורך כך בוצעו אימוני בינה מלאכותית אשר מטרתם לתייג אובייקטים בתמונה (Image Object Classification), מודל זה מקבל סטים של תמונות בהם מסומנים האזורים בהם נמצאים האובייקטים שמעניינים אותנו, אך הפעם אנו מצרפים לכל אזור (המייצג את האובייקט בתמונה) מהו הסיווג של אותו אובייקט, כלומר תווית עם תאור מילולי המתאר את האובייקט.
לאחר אימון המודל באמצעות מספר רב של תמונות הכוללות תוויות המציינות את המשמעות של האובייקטים השונים, המודל "לומד" לזהות את התכונות הייחודיות של כל אובייקט בתמונה ויעשה שימוש במשתנים אלו כדי לזהות אובייקטים בתמונות שהוא מקבל לצורך סווג ותיוג אותם אובייקטים על בסיס נתוני האימון.
כך המודל ידע לציין שברמת סבירות של 88 אחוז שהוא מזהה בצד הימני של התמונה שוטר, ובסבירות של 75 אחוז בצד השמאלי גנב.

זה הרעיון הכללי, ובצורה מאד מאד מופשטת, העקרונות המרכזיים בתהליך זיהוי ותיוג אובקייטים בתמונות מבלי להיכנס למורכבות והאלגוריתמיקה של אימון המודלים שפועלים מאחורי הקלעים.
האם מכונות יכולות ליצור תמונות
אז כפי שכבר הבנו תחום הראייה הממוחשבת התפתח מאד בשנים האחרונות ומכונות לומדות מצליחות לזהות ולהגדיר אובייקטים שונים בתמונה בצורה מדוייקת. אבל מה לגבי ההיפך, האם ניתן לצפות ממכונה לומדת לייצר נתונים חדשים (במקרה שלנו תמונות) ולא רק לנתח אותם.
זה בדיוק האתגר איתו התמודדו חבריו של איאן גודפלו (Ian Goodfellow) ב 2014 כהתכוננו לעבודת הגמר שלהם בתואר מדעי המחשב. הסיפור (מתוך הראיונות עם גודפלו ) הוא שהקבוצה יצא לחגוג את סיום לימודיהם בבר מקומי במונטריאול והתייעצו עם גודפלו בוגר תואר במדעי המחשב מאוניברסיטת סטנפורד כיצד ניתן לאמן מחשב לייצר תמונה חדשה.
התחום לא היה חדש לגמרי, חוקרים בעבר כבר השתמשו ברשתות עצביות ואלגוריתמים כמודלים "יצירתיים" בכדי ליצור תמונות, אבל התוצאות לא היו טובות והתמונות שנוצרו על ידי המחשב היו מטושטשות וחלקים רבים היו חסרים בתמונה.
גודפלו שהמשיך לחשוב על הבעיה עוד באותו ערב עלה על רעיון יצירתי להתמודד עם האתגר. להעמיד שני מודלים של בינה מלאכותית (רשתות עצביות) האחת מול השניה ולייצר בינהן סוג של תחרות (או קרב). גודפלו ישב עוד באותו ערב לבחון את התאוריה שלו ולפי דבריו הוא מצא פתרון לבעיה עוד באותו לילה.
פריצת הדרך - מודל GAN
המודל שפותח באותו לילה נקרא GAN - Generative Adversarial Networks, או מודל למידה חישובית. הטכניקה עוררה התרגשות עצומה בתחום למידת המכונה והפכה את גודפלו לסלבריטאי בינה מלאכותית.
פריצת הדרך של מודל הGAN הייתה שהוא לא רק למד (באמצעות אימון) לזהות דפוסים בנתונים קיימים (לדוגמא אובייקטים בתמונה- כפי שראינו בפרק הקודם ) אלא ליצור נתונים חדשים.
כאמור מודלGAN מורכב משני חלקים מרכזיים: מודל מאבחן (Discriminator) ומודל מייצר (generator), המודל המייצר אחראי ליצור תמונות חדשות ולשלוח אותם למודל המאבחן. המודל המאבחן אחראי להחליט האם התמונה שיצרנו נכונה על בסיס סט התמונות ששימשו לאימון שלו (בדומה לזיהוי התמונות בחלק הראשון של המאמר שלנו).
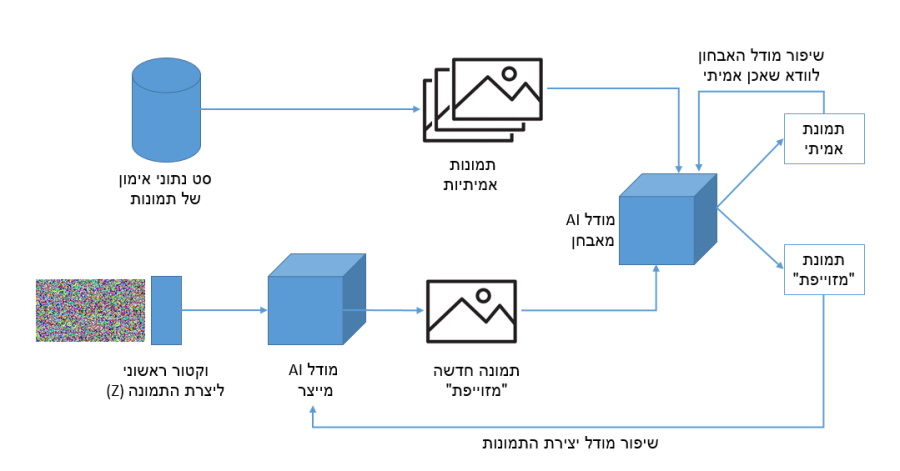
תמונה ננסה להסביר את הרעיון באמצעות אנלוגיה של בלשים וזייפנים. לצורך ההמחשה המודל המייצר שלנו יהיה הזייפן שרוצה להדפיס שטר מזוייף ולהטעות את כולם לחשוב שהוא אמיתי, והמודל המאבחן הוא הבלש שצריך לזהות האם השטר אמיתי או לא.
1. מכיוון שהזייפן שלנו עדיין לא מאומן ביצירת שטרות הוא מייצר בשלב הראשון שטר באיכות ירודה (שכולו פיקסלים רנדומליים) ושולח אותם לבלש בכדי לבחון האם הבלש יבחין שמדובר בזיוף.
2. הבלש שאומן באמצעות הרבה מאד תמונות של שטרות תקינים ומזוייפים, למד לזהות את ההבדל בין שטר תקין למזוייף. מכיוון שהשטר הראשון שנשלח אליו הוא הוא באיכות ירודה (רעש אקראי), הבלש מיד מדווח לזייפן שהוא יודע שהשטר מזוייף ותוך כדאי כך הוא לומד טוב יותר לזהות את השטרות המזוייפים שהזייפן מייצר.
3. הזייפן משפר את יכולת הזיוף שלו כתוצאה מכך שהוא נתפס על ידי הבלש ומנסה שוב לשפר את איכות השטר המזוייף שהוא מייצר, ושוב שולח אותו לבדיקת הבלש.
4. הבלש מבצע בדיקה נוספת של השטר המזוייף אל מול מאגר השטרות התקינים והמזוייפים שיש ברשותו (סט נתוני האימון) ומודיע לזייפן שגם הפעם הוא גילה שהשטר מזוייף.
5. תהליך זה ממשיך במחזוריות עד לשלב בו הבלש כבר לא יכול להבחין האם השטר תקין או מזוייף, כלומר הזייפן שלנו למד ליצר שטר מספיק קרוב לשטרות שהבלש מכיר ומבחינת הבלש השטר נראה אמיתי.
זו למעשה הדרך בא מודל GAN לומד בצורה "עצמאית" עם סט קטן יחסית של נתוני אימון לייצר תמונה חדשה.
תמונות מבוססות GAN פורצות למיינסטרים
באוקטובר 2018 בית המכירות הפומביות כריסטי'ס (Christie’s) עשה היסטוריה כאשר הוא הציע לראשונה במכירה פומבית יצירת אומנות שנוצרה באמצעות מודל הבינה המלאכותית GAN. הדיוקן העונה לשם "אדמונד דה בלאמי - Edmond Belamy" מציג תמונה מטושטשת עם פרצוף מרוח ללא אף וכתם במקום פה, לבוש במה שנראה כמעיל שמלה כהה מעל חולצת צווארון לבן.

מרחוק, הדיוקן בגודל 70 ס"מ על 70 ס"מ המודפס על קנבס ותלוי במסגרת עץ מוזהב, נראה כאילו הוא שייך למוזיאון לאמנות קלאסית. אבל במבט מעמיק יותר, החתימה של האמן שיצרה אותו - הנוסחה המתמטית הבאה G max D x [log (D(x))] + z [log (1 – D (G(z)))]מסגירה שהאמן לא היה אנושי.
הדיוקן שנוצר על ידי בינה מלאכותית הרעיד את עולם האמנות כשנמכר בסכום מדהים של 432,500 דולר, זינוק של 4,320 אחוזים מההערכה הגבוהה ביותר שניתנה ליצירה בתחילת המכירה, ועמדה על 10,000 דולר (סכום גבוהה בפני עצמו).

שנה לאחר המכירה של הדיוקן "אדמונד דה בלאמי", בימים הראושנים של שנת 2019, אמן גרמני בשם מריו קלינגמן (Mario Klingemann) הציג יצירה אינטרקטיבית בשם "Memories of Passersby I" שפרצה את גבולות הדיגיטל והועמדה למכירה פומבית בגלריית sotheby’s תמורת סכום מוערך הנע בין 38,500 ל 51,000 דולר.
קלינגמן התפרסם בזכות מייצגי אומנות מבוססי אלגוריתמים שהוא יוצר ומפרסם ברחבי הרשת כהוכחה ליכולת של מודלים מתמטיים ואלגוריתמים ליצר אומנות דיגיטלית. יצירת האמנות של קלינגמן - "Memories of Passersby I" היא למעשה מיצג פורץ דרך אשר בנוי משולחן עץ שנראה כמו רדיו עתיק בתוכו "מוסתר" מחשב אשר מחובר לשני מסכים ממוסגרים שעליהם מוצגים דיוקנאות של פרצופים גבריים ונשיים שמתחלפים בזמן אמת.

מאחורי המיצג עומד מודל בינה מלאכותית מבוסס GAN אשר הוזן על יד קלינגמן באלפי דיוקנאות מהמאות ה-17 עד ה-19. כחלק מתהליך אימון המודל קלינגמן עשה שימוש באפליקצייה בה הוא סימן למודל האם הדיוקן שהמערכת יצרה נראה טוב או לא, לצורך האימון הוא בנה אפליקציה קטנה דמויית טינד בה הוא מסמל בדפדוף ימינה או שמאלה האם התמונה שהמודל יצר נראית טוב או לא.
לסיכום
מודל הבינה המלאכותית GAN פתח עולם שלם של שימושים חדשים התחום הבינה המלאכותית היוצרת (ג'נרטיבית), ככל שעבר הזמן המודלים מבוססי GAN התפתחו והפכו לחכמים יותר ואיכות התוצרים השתפרו בהתאם. הבעיה עם מודלים מבוססי GAN, היא שהם יודע ליצור תמונות (או תוכן אחר) רק בתחום של סט האימון שלהם. באנלוגיה להמחשה שלנו המודל ילמד לייצר רק תמונות של שטרות כסף אך הוא או לא ידע לייצר תמונה של כמכונית או בית. אתגר נוסף הוא שהתהליך אקראי ברובו ושלא ניתן להנחות את המודל באמצעות טקסט כיצד ליצור את התמונה שאנו רוצים אלא.