פעם בהרבה מאוד שנים, מגיעה פריצת דרך טכנולוגית שגורמת לנו לחוש שאנחנו עדים לנקודת ציון היסטורית. כזו הייתה ההכרזה של OpenAI בתחילת 2021 על מודל בינה מלאכותית חדש שמסוגל ליצור איורים על בסיס פקודות טקסטואליות. הכרזה זו פרצה סכר של התפתחויות ושיפורים במודלים הג'נרטיבים בכלל, ובמודלי סינתוז התמונות בפרט.
אך לפני שאנו ממשיכים לפרקים הבאים בהם נלמד איך לשלוט בכלים אלו, לקחתי על עצמי משימה מורכבת שבה אנסה להסביר טכנולוגיה ומודלים מתמטיים מורכבים בשפה פשוטה ככל שניתן.
פריצת דרך באימון מודלים ליצירת תמונות
בשנים האחרונות נעשה שימוש בשני מודלים מרכזיים ליצירה של תמונות באמצעות בינה מלאכותית, מודלים שפותחו על בסיס מודל גאן (GAN) (אותו סקרנו במאמר הקודם) ומודלים שפותחו על בסיס מודל Variational Autoencoders - VAE.
אך פריצת הדרך כפי שכבר ציינתי התרחשה ביוני 2021 במחקר שפורסם על ידי חוקרים מחברת OpenAI תחת הכותרת "מודלי דיפוזיה ניצחו את מודלי גאן בסינתוז תמונות" - Diffusion Models Beat GANs on Image Synthesis
מחקר זה מבוסס על שלושה מחקרים קודמים שהיוו את הבסיס בפריצת הדרך של מודלי הדיפוזיה ליצירת תמונות. המחקר הראשון פורסם ב 2015 על ידי חוקרי בינה מלאכותית מאוניברסיטאות סטנדפור וברקלי, ועסק בנושא – למידה עמוקה בלתי מונחית באמצעות תרמודינמיקה ללא שיווי משקל (Deep Unsupervised Learning using Nonequilibrium Thermodynamics), מחקר זה עסק לראשונה במודלים ג'רטיביים בתחום הבינה המלאכותית אשר עשו שימוש ברעיון הדיפוזיה שהושאל מתחומי הפיזיקה.
המחקר השני שפורסם בשנת 2020 על ידי חוקרים מאוניברסיטת ברקלי היה למעשה שיפור והרחבה של המחקר הראשון והציע מודל משופר שנקרא Denoising Diffusion Probabilistic Model או בקיצור DDPM (בהמשך נרחיב על מודל זה).
המחקר השלישי מתבסס על מאמר של אלכס ניקול (Alex Nichol) ופראפולה דריוואל (Prafulla Dhariwal), שני מדעני נתונים בחברת ,OpenAI אשר פורסם באותה שנה - Improved Denoising Diffusion Probabilistic Models.
מחקרם שיפר את מודל יצירת התמונות באמצעות דיפוזיה תוך שיפור תהליך האימון, שיפור בארכיטקטורה של רשת הנוירונים המעורבות בתהליך, וכתוצאה מכך גם שיפור באיכות התמונות שנוצרו באמצעות המודל. מחקר זה היווה את הבסיס לפלפורמת יצירת התמונות Dall-E 2 ומשם ליישום באמצעותו ניתן לייצר תמונות חדשות מהנחיות טקסטואליות.
כיום שלושת הכלים המרכזיים ליצירת תמונות באמצעות בינה מלאכותית Dall-E 2 ,Midjourney ו Stable Diffusion עושים שימוש באותם עקרונות מרכזיים שפורסמו במאמרים אלו, כשכל כלי משפר את המודל ומממש אותו בצורה שונה בפלטפורמה שהונגשה לקהל המשתמשים.
הטכנולוגיה בבסיס מסנתזי התמונות.
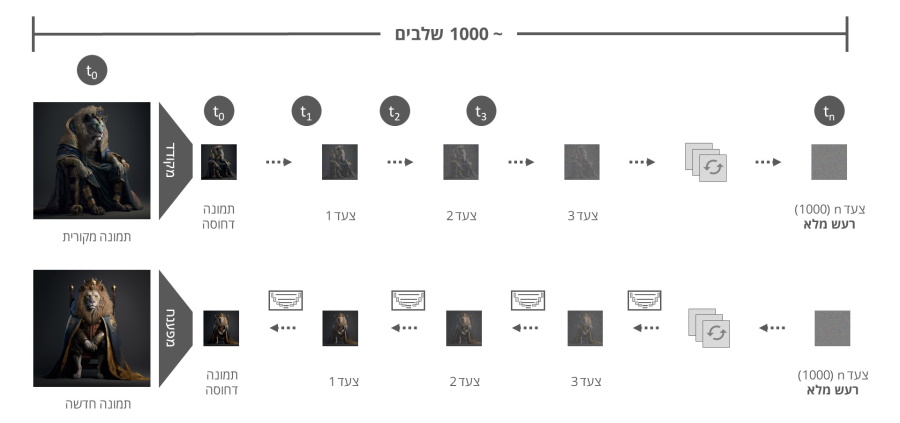
בכדי להבין כיצד כלים אלו עובדים ננסה להבין את העקרונות המרכזיים של מודל הדיפוזיה (DDPM) שהוצג בשנת 2020. בדומה למודלים גנרטיביים אחרים כמו GAN, VAE או מודלי זרימה, גם מודל הדיפוזיה יוצר תמונה מרעש (תמונה מפוקסלת). אבל כאן הדמיון בין הגישות נגמר כיוון שהדרכים בהן המודלים מפענחים את התמונה המקורית מהרעש שונות.
לצורך ההסבר נחלק את התהליך ל 4 שלבים מרכזיים :
שלב ראשון : שלב הדיפוזיה – Diffusion Process.
השלב הראשון בתהליך הדיפוזיה מתחיל בתהליך בו אנו מוסיפים רעש גאוסי לתמונה. בשפה פשוטה יותר אנו מטשטשים את התמונה כך שכל פיקסל בתמונה משתנה באופן אקראי עד לתוצאה הסופית בה התמונה מטושטשת (מפוקסלת) לחלוטין, ונראית כמו קובץ אקראי.
כמו במודל GAN אותו סקרנו בפרק הקודם, מטרת קובץ הרעש היא להוות נקודת פתיחה לתהליך יצירת תמונה החדשה.
מכיוון שהמטרה העיקרית שלנו בתהליך היא ללמד את הבינה המלאכותית לשחזר את התמונה למצב המקורי שלה, חוקרי הבינה המלאכותית מצאו שהדרך הטובה ביותר לשחזר תמונה מקובץ רעש (מפוקסל) היא באמצעות תהליך מדורג. ולכן בשלב הראשוני אנו יוצרים סדרה של תמונות כאשר לכל תמונה אנו מוסיפים כמות קטנה של רעש בצורה הדרגתית (אם כי לא לינארית) עד לתוצאה הסופית הרצויה שהיא קובץ תמונה מטושטש לחלוטין (רעש גאוסי).

אחד הפרמטרים החשובים לשלב הבא (שלב הפענוח) הוא כמות הצעדים הנדרשת כדי להרעיש את התמונה עד לקבלת התוצאה הסופית, נתון אשר ישמש אותנו בשלב השני לצורך שחזור התמונה המקורית מהרעש.
* התהליך אינו לינארי מכיוון שהחוקרים מצאו שהוספה לינארית של רעש יוצרת הרס מהיר מידי של נתוני התמונה. לכן לקראת השלבים האחרונים של הוספת הרעש לא ניתן להבחין בשינוי של הרעש שנוסף לתמונה, ומכאן שהיכולת לשחזר את התהליך הופכת להרבה יותר מורכבת.

שלב שני : שלב הפענוח – The Denoising U-Net.
השלב השני הוא השלב המשמעותי בתהליך בו אנו מאמנים את המודל (רשת נוירונים) לבצע תהליך הפוך של הסרת הרעש. מכיוון שבניסויים השונים נמצא שהסרה מוחלטת של הרעש מהתמונה הסופית לתמונה המקורית הוא תהליך מורכב ואיכות התמונות שנוצרו בתהליך הייתה נמוכה, החוקרים הציגו במחקר תהליך בו המודל מסיר את הרעש בצורה הדרגתית.

תהליך הסרת הרעש מבוצע בשלבים הפוכים לשלבים בהם הוספנו את הרעש בתהליך הראשון. בכדי לאמן את המודל אנו מספקים לו בכל פעם תמונה אחת במיקום שונה בסדרת התמונות המורעשות לצד הגדרת השלב בסדרה ממנה נלקחה התמונה.
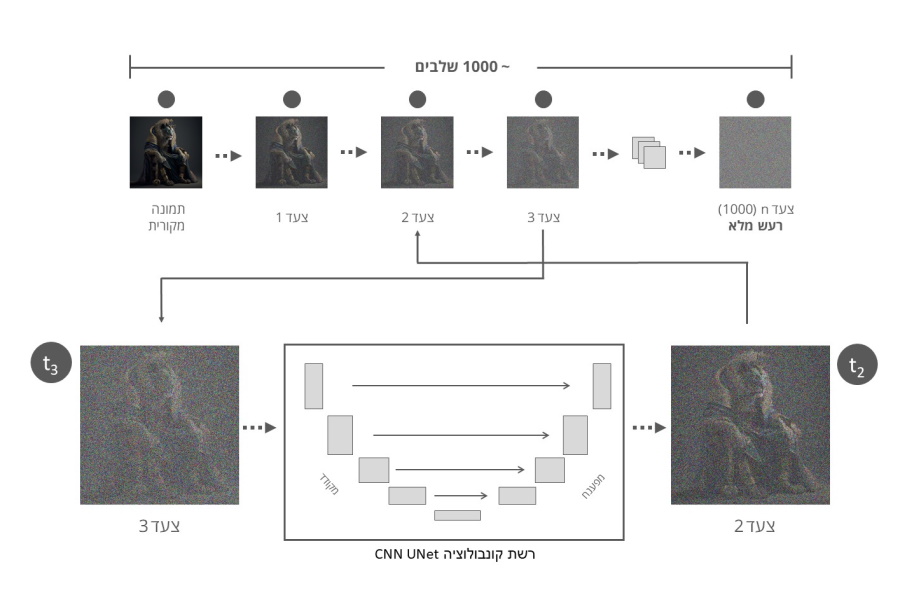
בכל שלב בתהליך הסרת הרעש, התמונה עוברת דרך רשת קונבולוציה (או רשת עצבית מתקפלת באנגלית -CNN – Convolutional Neural Network) מסוג U-Net אשר קרויה כך בשל צורת ה U שלה המורכב משני חלקים שונים : החלק המצמצם (המקודד - החלק השמאלי בתרשים) והחלק המרחיב (המפענח - החלק הימני בתרשים).
המטרה של החלק המצמצם (המקודד) הינה להקטין את גודל התמונה - כלומר להקטין את כמות המשתנים בתמונה תוך שמירה על הנתונים החשובים לנו לתהליך זיהוי הרעש וזאת בכדי להפוך את תהליך זיהוי הרעש בתמונה ליעיל וחסכוני תוך שימוש בהרבה פחות משאבים אל מול תהליך בו אותה פעולה מבוצעת על התמונה המקורית. לאחר שלב זיהוי הרעש החלק המרחיב (המפענח) של הרשת מחזיר את התמונה המצומצמת לגודלה המקורי.
החזרת התמונה לגודלה המקורי מתבצעת באמצעות קשרי דילוג (skip connections) בין המקודד למפענח עבור שכבות מקבילות בתהליך, וזאת על מנת לעזור למפענח לשחזר את התמונה לגודלה המקורי ולספק מידע אודות המיקום המדויק של כל פיקסל בתמונה המקורית.
במהלך האימון של רשת ה- U-Net היא מקבלת זוגות של תמונות, כאשר תמונה אחת היא התמונה המקורית והתמונה השנייה היא אותה תמונה עם הרעש שנוסף ותוייג. מודל ה-U-Net לומד להבדיל בין התמונה המקורית לתמונה הרועשת על ידי לימוד מאפייני הרעש. בסיום תהליך האימון, רשת ה U-Net משמשת אותנו כדי לזהות ולהסיר את הרעש מהתמונות שמועברות למודל על ידי שימוש בתכונות שנלמדו באימון.
בחזרה לתהליך המרכזי שלנו..
בכל שלב בתהליך בהינתן התמונה והמיקום שלה בסדרה, מודל ה U-Net "מנחש" את סך כל הרעש בתמונה, אך מסיר רק חלק יחסי של הרעש, כך שהתוצאה תהיה התמונה הקודמת בסדרה (t-1), למעשה התוצאה היא התמונה (הקודמת) הנקיה יותר בסדרה.
המחקר של OpenAI הציג ביצועים טובים יותר כאשר המודל מסיר את הרעש שנוצר באותו שלב בסדרה, כלומר הסרה הדרגתית של הרעש, וזאת במקום הסרה של כל הרעש בבת אחת במטרה לנסות לשחזר את התמונה מהשלב הראשון בסדרה.
כחלק מתהליך האימון של מודל הדיפוזיה, אנו מספקים למודל בכל שלב את כמות הרעש לאותה תמונה בסדרה, וזאת על מנת לוודא שהמודל זיהה את כמות הרעש בצורה נכונה אל מול סט נתוני האימון. במידה וכמות הרעש שהמודל זיהה באותו שלב אינה תואמת את כמות הרעש שנוספה לאותה תמונה בסדרה, מבוצע תיקון למודל ומריצים אותו מחדש.
כך תהליך הסרת הרעש חוזר על עצמו בצורה מחזורית עד שהתהליך מגיע לנקודת ה 0 שהיא נקודת ההתחלה בתהליך הוספת הרעש.
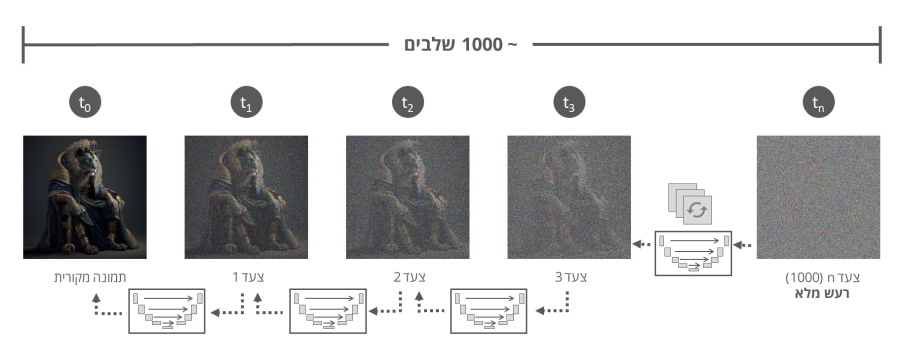
בצורה זו המודל לומד להסיר בצורה הדרגתית את הרעש בכל שלב עד שהוא מגיע לצעד 0 בתהליך בו הוא מציג תמונה קרובה ככל שניתן לתמונה המקורית ממנה החל תהליך הוספת הרעש.
לבסוף לאחר שהמודל אומן לשחזר בצורה הדרגתית תמונות מרעש מוחלט, ניתן לספק לו קובץ שהוא רק רעש והמודל יבצע תהליך הסרה של הרעש על בסיס המאפיינים שנלמדו בתהליך האימון וזאת עד לקבלת תמונה אשר קרובה במאפיינים שלה (למעשה נראית) קרובה לתמונות בסט האימון של המודל.
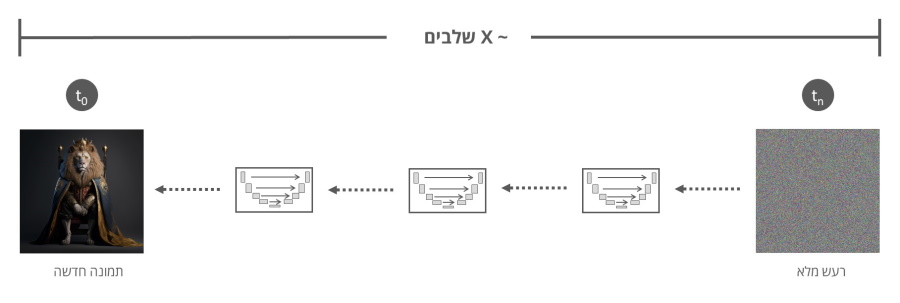
שיטה זו שימשה לאימון הכלים המובילים כיום : ,Dall-E 2 Midjourney ו Stable Diffusion תוך שימוש במיליוני תמונות מרחבי רשת האינטרנט.
בסוף התהליך מתקבל מודל בינה מלאכותית שיכול לייצר תמונות אקראיות באיכות גבוהה, תוך שמירה על דמיון מירבי לסט התמונות אשר שימשו לאימון המודל. זאת הודות לתהליך ההדרגתי בו מוסר הרעש מהתמונה תוך שמירה על מרבית המאפיינים של התמונות מסט האימון.
שיפור התהליך באמצעות דחיסת התמונה
באפריל 2022 הוצג מחקר נוסף ומשמעותי בתחום מודלי הדיפוזיה בשם - High-Resolution Image Synthesis with Latent Diffusion Models – המחקר נועד להתמודד עם האתגר המרכזי של מודלי הדיפוזיה הקיימים והוא המשאבים הנדרשים להסרה של רעש מתמונות גדולות ברזולוציה גבוהה.
המחקר הציג דרך חדשה להתמודד עם תהליך הדיפוזיה הדו שלבי שהצגנו עד כה באמצעות דחיסה של התמונות עליהן מבוצע התהליך. כלומר, במקום לבצע את כל התהליך על התמונה המקורית אנו מבצעים את תהליך הדיפוזיה על קובץ תמונה דחוס שמייצג את התמונה המקורית.
למודל החדש שהוצג במחקר ארבעה יתרונות מרכזיים :
1. היכולת לבצע את תהליך יצירת התמונה מרעש באמצעות מודל דיפוסיה שמסוגל לעבוד במעבדים (GPU) "ביתיים" (כלומר מעבדים של מחשבים רגילים) במקום בכוח המחשוב העצום שנדרש לאמן את המודל של Dall-E ו Dall-E 2 לדוגמא.
2. יכולת לבצע את התהליך בצורה הרבה יותר מהירה לאור הקטנת משאבי המחשוב הנדרשים לתהליך.
3. עובדה זו סייעה להפיץ את המודל של Stable Diffusion כקוד פתוח שמאפשר למתכנתים רבים להריץ אותו במחשבים ושרתים אישיים / מקומיים מה שהגדיל את השימושים והיישומים במודל.
4. הסרת הרעש בסביבה דחוסה (ה Latent Space כפי שהוא מוצג במחקר) אפשרה לשלב בצורה טובה יותר את ההנחיות הטקסטואליות ליצירת התמונה החדשה שאנו רוצים לקבל בסוף התהליך. (על כך בסעיף הבא).
בניגוד למודל החדש שהוצא בפרסום האחרון, מודלי הדיפוזיה ה"ותיקים" אימנו את המודל שלהם על תמונות קטנות ( 256*256 פיקסלים(. בסיום תהליך יצירת התמונה היה צורך להגדיל את התמונה שנוצרה באמצעות מודל דיפוזיה נוסף בשם Super-Resolution שנועד לשדרג את התמונה הקטנה ולהגדיל אותה תוך חידוד התמונה ושיפור האיכות שלה, עד שמתקבלת בסוף התהליך תמונה גדולה ברזולוציה גבוהה.
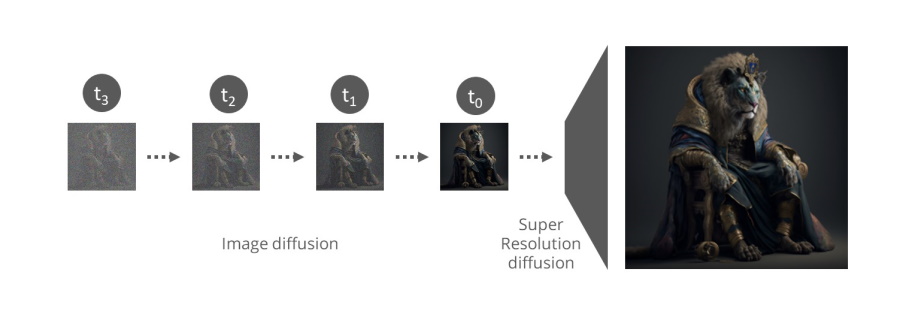
כאמור, במודל הדיפוזיה החדש שהוצג במחקר נוספו שני שלבים מובנים לתהליך, בתחילת התהליך מקודד מקבל את תמונה ומקטין אותה לקובץ דחוס ומוקטן, את הרעש הפעם אנו מוסיפים בהדרגה לתמונה הדחוסה בדיוק באותו תהליך דיפוזיה שהצגתי בסעיף הקודם במאמר זה. גם תהליך הפענוח דומה, אלא שמודל ה U-Net מבצע את זיהו הרעש על הקובץ הדחוס בצורה מחזורית עד לקבלת תמונה דחוסה הקרובה לתמונה המקורית שסופקה למודל בתחילת התהליך. בסיום מודל פיענוח מקבל את התמונה הדחוסה שנוצרה, ומרחיב אותה חזרה לקובץ גדול תוך שיפור איכות התמונה.
(מודל זה מזכיר מאד את המודל Glide שהוצג בדצמבר 2021 על ידי OpenAI, המודל שסלל את הדרך ליצירה של תמונות באמצעות הנחיה. גם במודל Glide שהוצג על ידי OpenAI נעשה שימוש בקובץ מוקטן של התמונה המקורית לצורך תהליך הדיפוזיה - הסרת רעש ויצירת תמונה חדשה).
עד כה סקרנו את תהליך יצירת התמונות באמצעות מודל הדיפוזיה כפי שהוצג במחקרים האחרונים. אך עדיין חסר לנו רכיב מאד משמעותי בתהליך. היכולת להנחות את המודל ליצור תמונות לפי ההוראות הטקסטואליות והגרפיות (באמצעות תמונה) שלנו.
שלב אחרון ומכריע - הוספת היכולת לשלוט במודל יצירת התמונות.
להשלמת התמונה של תהליך יצירת התמונות אנו מוסיפים שני רכיבי בינה מלאכותית נוספים. הראשון הוא מודל GPT המוכר לרבים מאיתנו בזכות היישום המוכר ביותר שלו כיום ChatGPT של OpenAI, ומודל נוסף בשם CLIP גם הוא מבית OpenAI.
בכדי להבין כיצד ההנחיות הטקסטואליות משתלבות בתהליך נתחיל בסקירה והבנה של מודל CLIP שהוצג לראשונה על ידי OpenAI בתחילת שנה 2021.
CLIP הוא מודל זיהוי ותיוג תמונות המבוסס על טכנולוגיית Generative Pre-trained Transformer 3 או בשמה המקוצר GTP-3, מודל לעיבוד שפה טבעית באמצעות למידה עמוקה (Deep Learning).
CLIP נוצר בכדי לפתור שני אתגרים מרכזיים בתחום הראייה הממוחשבת: הקטנת העלות הידנית הכרוכה ביצירת מערכי נתונים לאימון מודלים מבוססי ראייה ממוחשבת, והקטנת המאמץ הנדרש למודלים סטנדרטיים אלו כאשר אנו רוצים להתאים אותם למשימות חדשות בתחום.
על מנת לפתור אתגרים אלה, מודל CLIP אומן באמצעות 400 מיליון צמדים של תמונות והתאור שהוצמד אליהן באתרי האינטרנט כחלק מההנגשה של האתר לבעלי מוגבלויות או הקידום שלו במנועי החיפוש.
(מודל CLIP אינו מנסה לסווג תמונות אלה לבצע התאמה בין התמונה לתאור שלה זאת בניגוד לאופן בו מבוצע אימון "מסורתי" לזיהוי וסייוג תמונות באמצעות תיוג ידני כפי שראינו במאמר הקודם.)

מודל CLIP מאומן באמצעות שני מקודדים, האחד הופך טקסט לוקטור (אמבדינג לפי הגדרת OpenAI) שהוא למעשה ייצוג מתמטי של הטקסט, והשני הופך תמונות לוקטור שהוא ייצוג מתמטי של התמונה.
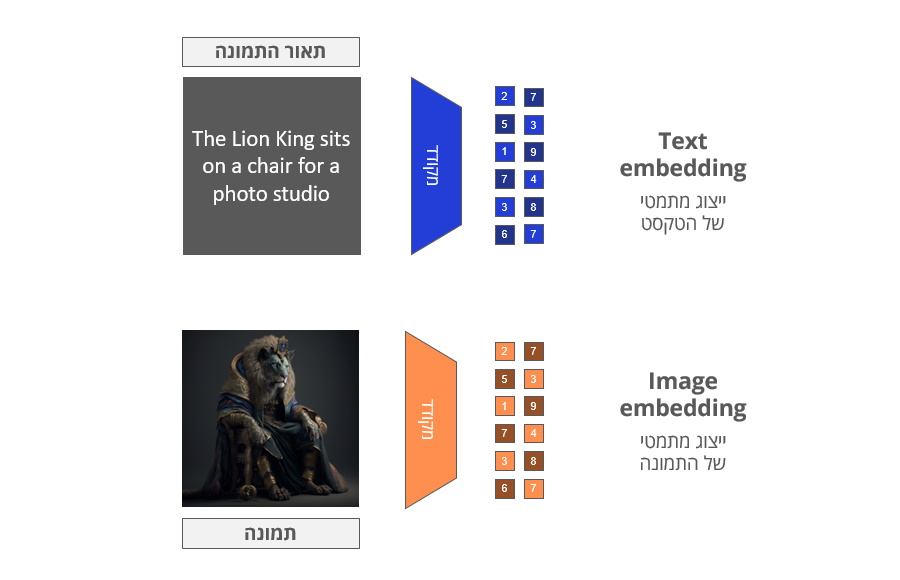
לאחר הקידוד של הטקסט והתמונה CLIP מנסה למצוא את הדימיון בין הוקטור המתמטי של טקסט לוקטור המתמטי של התמונה.
על ידי חזרה על תהליך ההתאמה בין וקטור התמונה לוקטור הטקסט באמצעות מערכי נתונים גדולים כפי שניתנו ל CLIP, שני המקודדים אומנו כך שהוקטור המתמטי שמייצג את התמונה של "מלך האריות" והטקסט "מלך
האריות יושב על כסא בסטודיו" היו מאד דומים. תהליך האימון כולול גם דוגמאות שליליות של תמונות וטקסטים שאינם תואמים, להם המודל צריך להקצות ציוני דמיון נמוך.
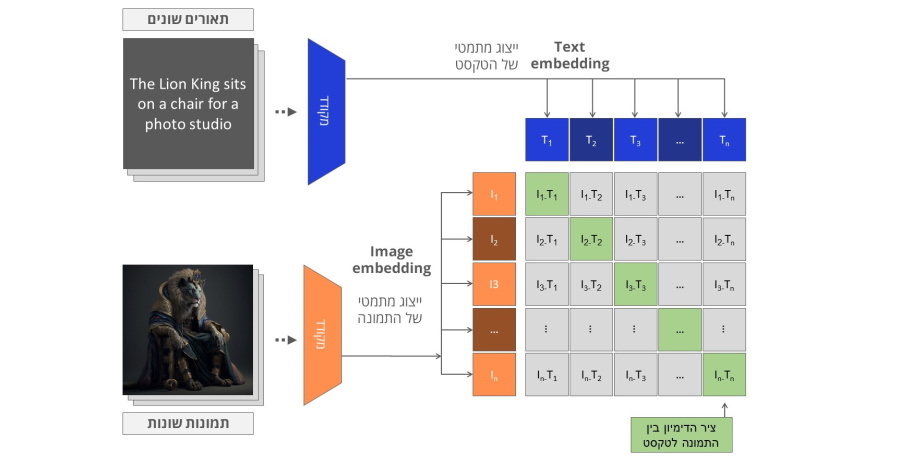
(* אילוסטרציה מות האתר הרשמי של Clip)
שני הכלים המרכזיים כיום עושים שימוש בגרסאות שונות של CLIP.
Dall-E 2 של OpenAI עושה שימוש במודל CLIP המלא והסגור של החברה, בעוד ש Stable Diffusion עושה שימוש ב OpenClip - גרסה בקוד פתוח המבוססת על מודל CLIP של OpenAI.
שילוב טכנולוגיית CLIP בתהליך יצירת התמונות (או יותר נכון בתהליך הסרת הרעש) הוא המפתח ליכולת להנחות את מודל הדיפוזיה ליצור תמונות אשר מבוססות על ההנחיה הטקסטואלית או הגרפית (תמונה שמועברת למודל).
בשני המקרים גם כאשר אנו מספקים תמונת ייחוס או הנחיה טקסטואלית למודל הדיפוזיה, אלו משולבים בצורת הוקטור המתמטי שנוצר באמצעות מודל ה CLIP בכל אחד משלבי הסרת הרעש באמצעות מודל ה U-Net שהזכרנו בשלב הפיענוח של מאמר זה.
באמצעות אלמנט נוסף שנקרא Attention אשר משולב בתהליך הסרת הרעש בכל שלב במחזור הסרת הרעש, אנו "מכוונים" את המודל להתקרב לוקטור המתמטי אשר מייצג את ההנחיה שלנו. כלומר הוקטור המתמטי של ההנחיה הטקסטואלית משמש את המודל ליצירה של תמונה עם וקטור מתמטי שיהיה קרוב (דומה) ככל הניתן לוקטור המתמטי של ההנחיה. כך בכל שלב של הסרת הרעש התמונה המתבהרת מתקרבת להנחיה שהמודל קיבל.
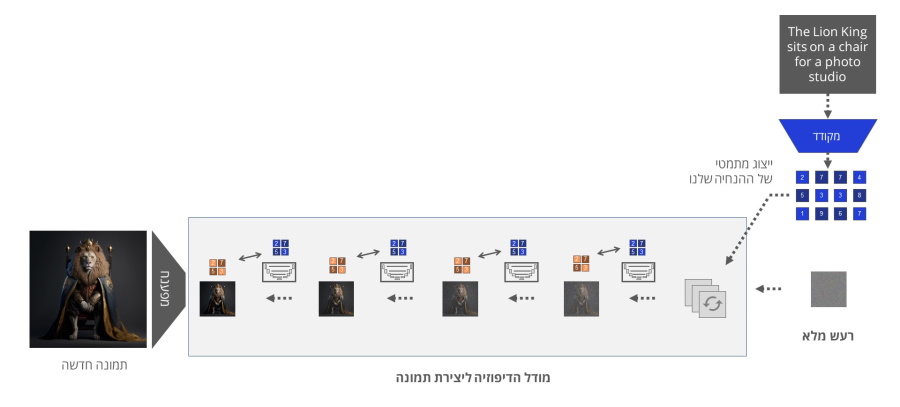
בסיום התהליך מודל הפענוח מגדיל ופורס את התמונה כך שהתמונה הסופית שתתקבל תיהיה ברזולוציה ובאיכות גבוהה. ו.. וואלה יש לנו סטודיו לצילום חיות בר אנושיות.... או כמובן כל דבר אחר שיעלה בדימיונכם היצירתי.

ובלי סיכומים נוספים, אם הצלחתם להגיע עד כאן מגיע לכם מחיאות כפיים.